MCP is eating the world—and it's here to stay

Young-jin Park
Software Engineer
Update (March 2026)
We’ve gone deeper on what actually makes MCP work well in practice.
In a new post, we share evaluation results showing that SDK code mode — where the model writes and executes integration code using an idiomatic SDK — delivers state-of-the-art accuracy and performance for complex API tasks.
If you’re building or exposing an API via MCP, we recommend reading:
“SDK code mode shows SotA accuracy and performance for agents using APIs.”
It includes detailed eval results across multiple MCP server configurations, real-world failure cases, and guidance on how to implement SDK code mode effectively.
Despite the hype, Model Context Protocol (MCP) isn’t magic or revolutionary. But, it’s simple, well-timed, and well-executed. At Stainless, we’re betting it’s here to stay.
“MCP helps you build agents and complex workflows on top of LLMs”. If you’ve paid attention, you know we’ve been here before. There are numerous past attempts at connecting the world to an LLM in a structured, automatic way.
Function/tool calling: Write a JSON schema, the model picks a function. But you had to manually wire each function per request and assume most of the responsibility for implementing retry logic.
ReAct / LangChain: Let the model emit an
Action:string, then parse it yourself—often flaky and hard to debug.ChatGPT plugins: Fancy, but gated. You had to host an OpenAPI server and obtain approval.
Custom GPTs: Lower barrier to entry, but still stuck inside OpenAI’s runtime.
AutoGPT, BabyAGI: Agents with ambition, but a mess of configuration, loops, and error cascades.
Heck, even MCP itself isn’t new—the spec was released by Anthropic in November, but it suddenly blew up in February, 3 months later.
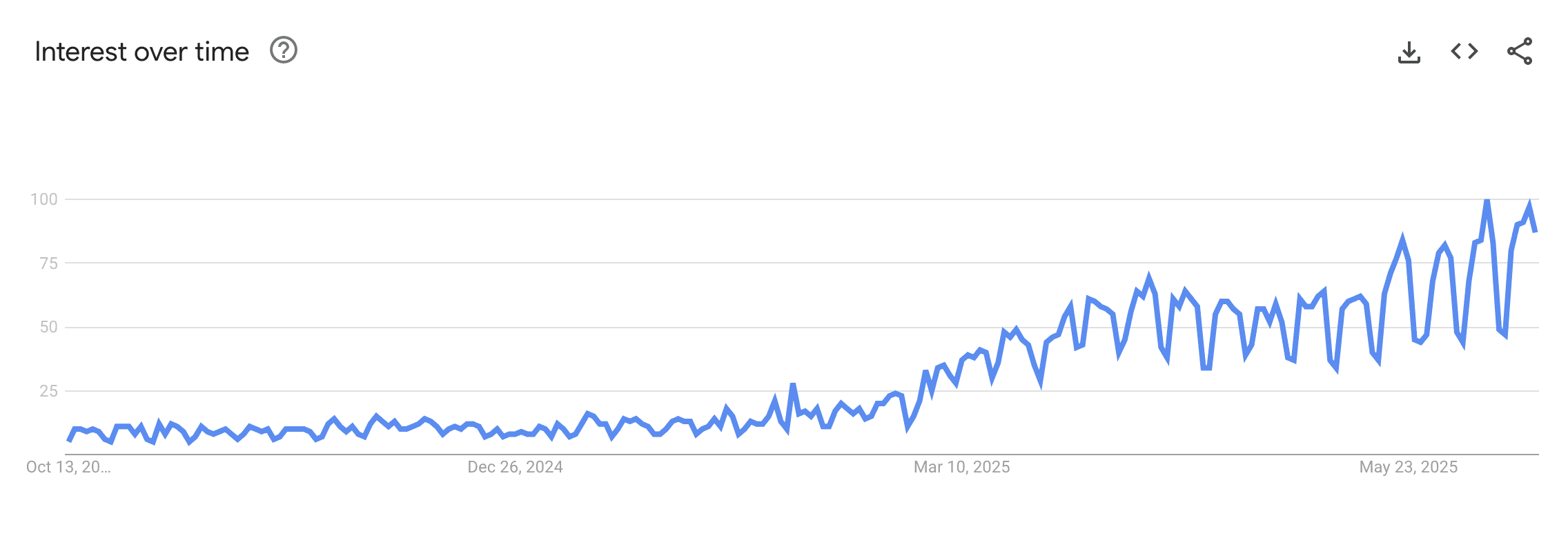
Why is it that MCP is seemingly in ascent, while previous attempts fell short?
Why is MCP eating the world?
1. The models finally got good enough
Early tool use was messy—at best—due to unreliable models. Even basic functionality required extensive error handling—retries, validation, and detailed error messages were necessary just to get complex workflows running.
Tool use in an agentic setting requires a high standard of robustness. Those who used earlier coding agents know the perils of context poisoning—when a nonsensical output from your agent sends the rest of the conversation into an inescapable spiral. These dangers only multiply as you add more tools.
With newer models, LLMs are good enough that they don’t get sucked into pits of despair and they can usually recover from mistakes. Of course, models and agents are still far from perfect—the better models are pretty slow, context sizes are still limited, and performance degrades when more and more context is present.
What’s important is that the models are good enough—once models cross that threshold, the overhead of integrating tool use drops dramatically. MCP just showed up right on time.
2. The protocol is good enough
Earlier tool interfaces were tied to specific stacks:
OpenAI’s function calling only worked in their API.
ChatGPT plugins needed their runtime.
LangChain tools were tightly bound to their prompt loop.
You couldn’t just take a tool from one setup and use it somewhere else, every platform needed its own wiring for every tool.
To make matters worse, translating connectors to the various platforms was not trivial: each provider supports slightly different capabilities, such as supporting different dialects of JSON Schema. To support retries, you had to figure out a way to append messages and create a new completion, which was slightly, annoyingly different between providers.
There were also the less explicit footguns, like cases where the same rough prompt performed significantly worse between providers due to small details in how you threaded through the messages.
MCP addresses these issues by providing a shared, vendor-neutral protocol. You define a tool once, and its accessible to any LLM agent that supports MCP.
Of course, compatibility problems aren’t fully resolved. In practice, getting MCP to work with all platforms remains a challenge—and the lack of an auth standard at the beginning of the roll out made integrations more challenging.
Still, the promise of MCP is important: if you’re developing a tool, you just need to comply with the MCP standard—the rest is a bug in someone else’s code. It’s easier to develop something new when you’re not fighting the world to make it happen.
Although the protocol isn’t perfect, it’s arguably good enough. As an abstraction, the protocol sets clear boundaries between the tool and the agent, which lets tool developers focus on tools and agent developers focus on agents. Exposing the right amount of detail in an API sounds easy, but is actually an art: at Stainless we call this “designing at the right altitude”. In our experience, when an API is designed at the right altitude, it just doesn’t go away.
3. The tooling is good enough
MCP’s tooling is straightforward, high-quality, and relatively easy to approach. SDKs are available in many languages, which makes integrations easy no matter what stack you use.
As an example, we’ll take a look at the Python SDK, though every SDK shares the following rough shape:
Something that makes it easy to define tools (decorators for Python functions)
A runtime to start the MCP Server
A basic MCP Client to interface with the server
Define a tool
Start a local MCP server:
That’s it—now the tools in that module are available to any MCP client, without unnecessary scaffolding or worrying about retries and agents. The lower barrier means that you can build and share tools faster—and reuse them across environments, in your CLI tools, your IDE, agents, web services, and more.
Of course, developing great MCP tools still requires a lot of work, including curating descriptions and paying attention to context usage, but what matters is that you can get started quickly and see the impact right away.
There’s a small lesson here: developer ergonomics matter. The difference between a platform achieving widespread adoption or dying in obscurity is sometimes attributable to just a small change in friction.
4. The momentum is good enough
To state the obvious, momentum is key to the success of any platform, protocol, or standard. A protocol is only as good as the clients and servers that adopt the framework.
On the client side, MCP adoption is already near-universal: OpenAI has adopted MCP in their agents SDK and Google's Deepmind is throwing their weight behind it. With that, all the major foundational model providers are now onboard. There are also many agent integrations, including Cursor, Cline, and Zed.
On the server side, we’ve seen API-first companies race to expose their services as MCP tools. Even where first-party tools aren't available, third-party servers fill the gaps.
Beyond the core software powering MCP, a rich ecosystem of independent resources is emerging:
Registries (awesome-mcp-servers, smithery.ai, postman, glama.ai)
Services (Cloudflare, Vercel)
Tutorials (glama.ai, towardsdatascience.com)
Courses (huggingface)
Events (MCP Night)
Momentum wasn’t built overnight—Anthropic’s team did a great job of advancing the ecosystem, such as writing excellent first party documentation, providing talks, hosting events, and working directly with companies to bootstrap a world where MCP is already compelling.
Momentum incentivizes the community to build and publish tools, which in turn makes agents more powerful, which in turn further accelerates community adoption.
As MCP becomes more commonplace, it’s likely foundational model providers will start training on the usage patterns. This influx of data will undoubtedly make the models even better at agentic tasks, cementing MCP in how we think about APIs in the future.
We think it’s going to stay
MCP is in the zeitgeist, but being in the zeitgeist historically hasn't meant longevity, so it's reasonable to approach MCP with a healthy dose of skepticism.
Despite this skepticism, we’re convinced MCP is going to stay: because it’s good enough, and it’s good enough in ways that previous technologies weren’t. And it’s not just us: our API-first customers see MCP servers as a core part of their API. We’re making a bet on MCP.
Originally posted
Jun 21, 2025