Publish your SDKs
Once you are satisfied with your SDK, you can distribute it to end users by publishing it to a package registry, like npm, PyPI, or RubyGems. After publishing, the generated SDK code will be moved to a GitHub repository that you own, where it will be picked up by package registries.
The Stainless-managed release flow handles the versioning and changelogs expected from a production-quality SDK. You can even automate this process so changes to your OpenAPI specification will trigger new releases.
1 Link production repos
Section titled “ Link production repos”Before you publish an SDK, we push the generated code to a staging repo
under the stainless-sdks GitHub organization. When your SDK is published, we
instead push the generated SDK code to a GitHub repo you own, called the
production repo.
Install the Stainless GitHub app
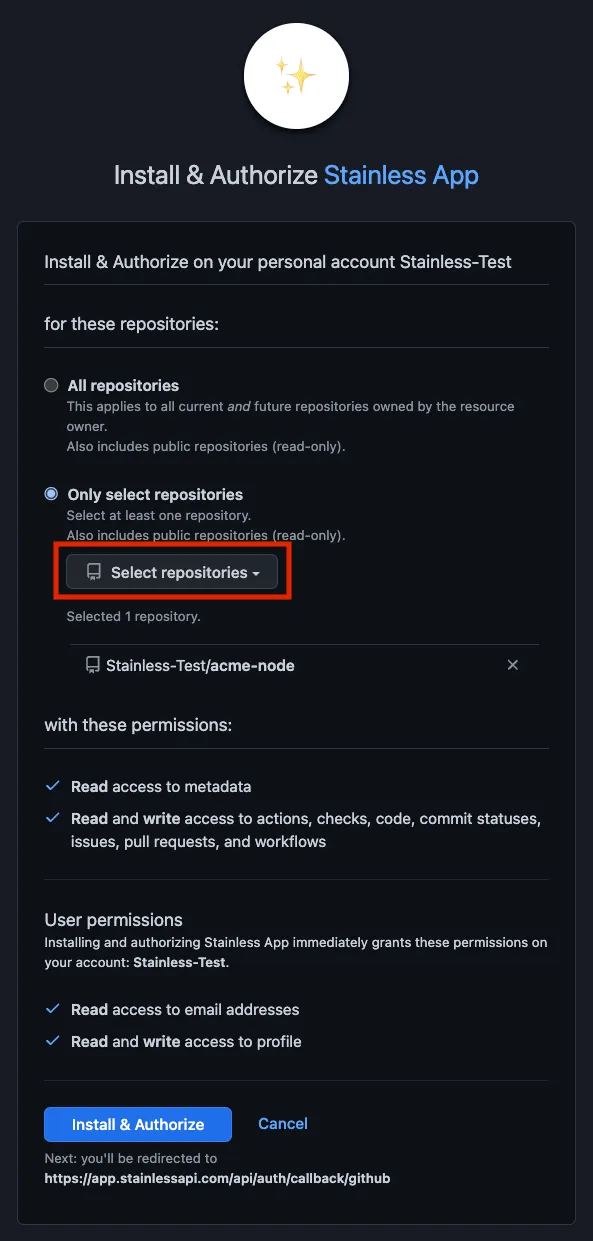
Section titled “Install the Stainless GitHub app”If your Stainless organization does not already have the Stainless GitHub app installed, you’ll need to install it first.
- In the Stainless dashboard, navigate to your project.
- Navigate to Release > Production repos.
- Follow the installation flow. When prompted, select which repos the Stainless GitHub app can access.
- Once repos have been selected and permissions have been reviewed, click Install & Authorize.
Choose a production repo
Section titled “Choose a production repo”After installing the Stainless GitHub app, you can then choose or create the production repo for each SDK.
We recommend choosing a name that meaningfully identifies your SDK. For
example, <company-name>-python is a common choice for Python SDKs.
The repo can be public or private.
- In the Stainless dashboard, navigate to your project.
- Navigate to Release > Production repos.
- If the Stainless GitHub app is installed, you will see a list of languages for your project. For each SDK you want to publish, use the dropdown to choose or create its production repo.
- Optionally, configure which branch of the production repo to push code to, by selecting it from the dropdown next to the repo name.
2 Connect package registries
Section titled “ Connect package registries”Package registries like npm and PyPI make it easy to distribute your packages to your users. After an initial setup, Stainless can automatically publish code from your production repo to various package registries.
Each target has specific publishing requirements and workflows. See the target-specific documentation for detailed setup instructions:
- TypeScript - Publish to npm and JSR (Deno)
- Python - Publish to PyPI with API tokens or trusted publishing
- Go - Automatic publishing via GitHub (no additional setup required)
- Java - Publish to Maven Central via Sonatype
- Kotlin - Publish to Maven Central via Sonatype
- Ruby - Publish to RubyGems
- PHP - Publish to Packagist
- C# - Publish to NuGet
- Terraform - Publish to Terraform Registry
- CLI - Publish to Homebrew
- OpenAPI - Automatic publishing to GitHub repository
- MCP - Publish to npm and Docker Hub
Versioning and releases
Section titled “Versioning and releases”Whenever your SDK changes because of an update to your OpenAPI spec,
your Stainless config, or our code generation, we push the
changes to the next branch of your production repository.
A release PR is then created against the main branch, which collects
individual changes as commits until you are ready to release them. By default,
we will never merge release PRs until they’re reviewed. This leaves the release
frequency up to you.
Your first release will be Release 0.1.0-alpha.1, meaning that the first release published to your package
manager will have an alpha tag.
Stainless will increment the version used in each subsequent release PR based on the prior one. We use the semantic information of the commits in the release to find the next available version, and for this reason commits should use the Conventional Commits to ensure versioning is correctly and automatically incremented:
- Breaking changes increment the major version number (if and only if the version is already at least
1.0.0) - Features increment the minor version number
- Fixes increment the patch number
How to customize the release version
Section titled “How to customize the release version”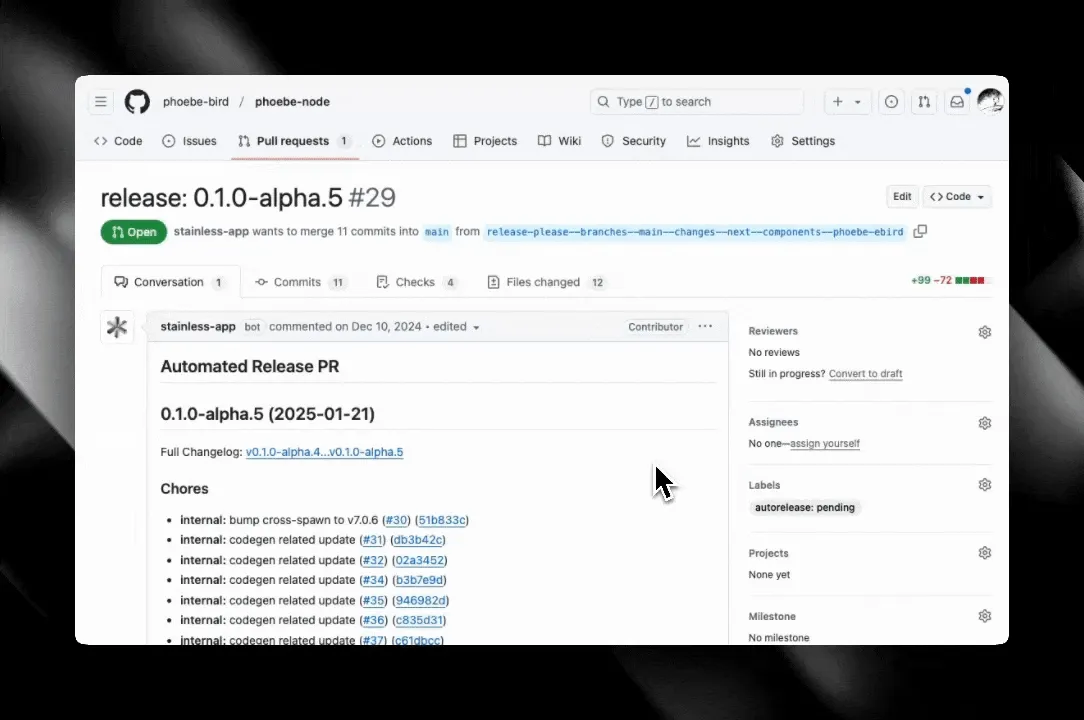
You can override our suggested version by modifying the PR title. Doing so will propagate your provided version (including any alpha or beta tags) to the release in GitHub and your package manager. We recommend:
- Staying in the alpha or beta stage while your SDKs still have diagnostic errors
- Staying in the 0.0.x range while your SDKs still have diagnostic warnings
- Staying in the 0.x.y range while your SDKs still have unacknowledged diagnostic notes
- Moving to 1.0.0 once your SDK has none of the above
We use semver-valid version numbers for releases.
How to move out of alpha
Section titled “How to move out of alpha”Once you’re ready to move out of an alpha stage, the only thing you need to do is customize the release version to the appropriate version. In most cases the next version after alpha should be 0.0.1.
If you don’t have a release PR, you can make an empty commit on the next
branch of your production repo with a Conventional Commit message.
Development and release flow
Section titled “Development and release flow”Stainless pushes code to various GitHub repos:
- Stainless config repo
- Stainless SDK repos
- Your production repos
Release flow
Section titled “Release flow”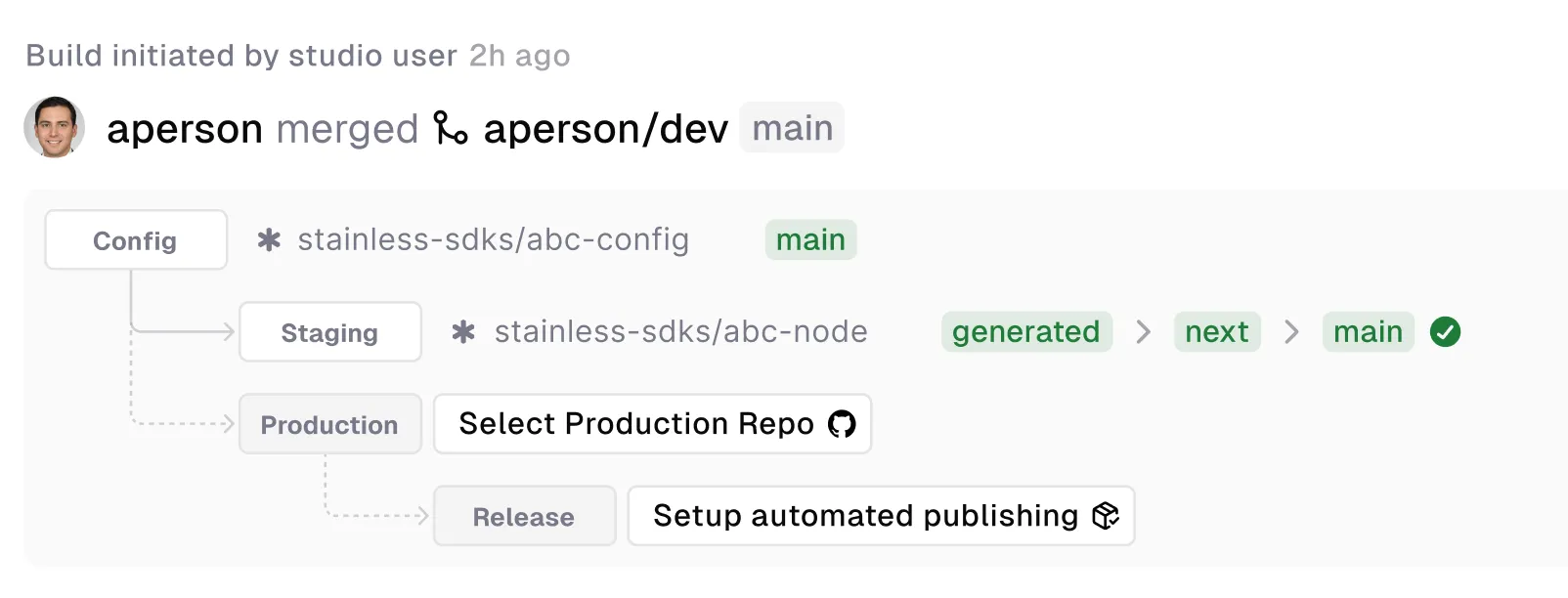
Stainless uses a few branches in your production repository to manage the release process:
main/master: The target branch of your repository. This defaults tomainbut can be configured per language usingproduction_repo.next: This branch is used to collect changes for the next release. Stainless will create Release PRs based on the changes in this branch.generated: The branch where Stainless pushes generated code from the Studio. This branch represents the latest generated code before any custom code changes are applied.release-please--*: Temporary release branches created and managed by our GitHub App. These branches are based onnextand are used to create release PRs.