SDK code mode shows SotA accuracy and performance for agents using APIs

Pierce Clark
Software Engineer

Kevin Whinnery
Head of Marketing & DevRel
Model Context Protocol (MCP) has rapidly grown in popularity, fueled in part by the promise of standardizing tool calling. But despite early traction, we haven’t seen a wave of AI agents composing complex API calls via MCP. Along with security challenges, two key limiting factors have been accuracy and token efficiency.
In recent months, code execution was detailed by Anthropic as a way to address token inefficiency with standard MCP tool calling methods. Cloudflare shared similar findings, and demonstrated excellent token efficiency while still exposing a broad range of functionality to a model.
At Stainless, we’ve observed that “SDK code mode” - a code execution technique using API-specific SDKs to generate integration code - provides state-of-the-art results for models operating an API via MCP.
When agents generate code using idiomatic SDKs, consult both API reference and narrative docs, use API-specific type checking, and receive more relevant error messages, they can generate code for complex API interactions with higher accuracy over fewer turns. Combined with the token efficiency benefits of code execution generally, SDK code mode provides an effective means of powering complex API integrations via MCP.
Stainless-generated MCP servers use this technique today. If you’ve had frustrating results using MCP to operate your API, we’d encourage you to try SDK code mode and reevaluate your results.
In this post, we’ll share more information about how SDK code mode works and examine eval results for this technique with a real world API integration.
How does SDK code mode work?
Agents like ChatGPT, Claude, and Cursor (or more autonomous software agents) can use MCP servers that enable them to operate external systems. For MCP servers that want to expose a complex API, creating tools for every possible operation in the API produces disappointing results. Tool definitions and responses eat into the context window, making each request slower, more expensive, and less intelligent over time.
MCP servers using code mode give the model access to complex APIs by having the model write code to accomplish its desired task. Because of this, each tool call can do multiple tasks at once via chained API calls, without using any additional space in the context window. In other words, context usage doesn’t scale with the complexity of the task the model is trying to accomplish.
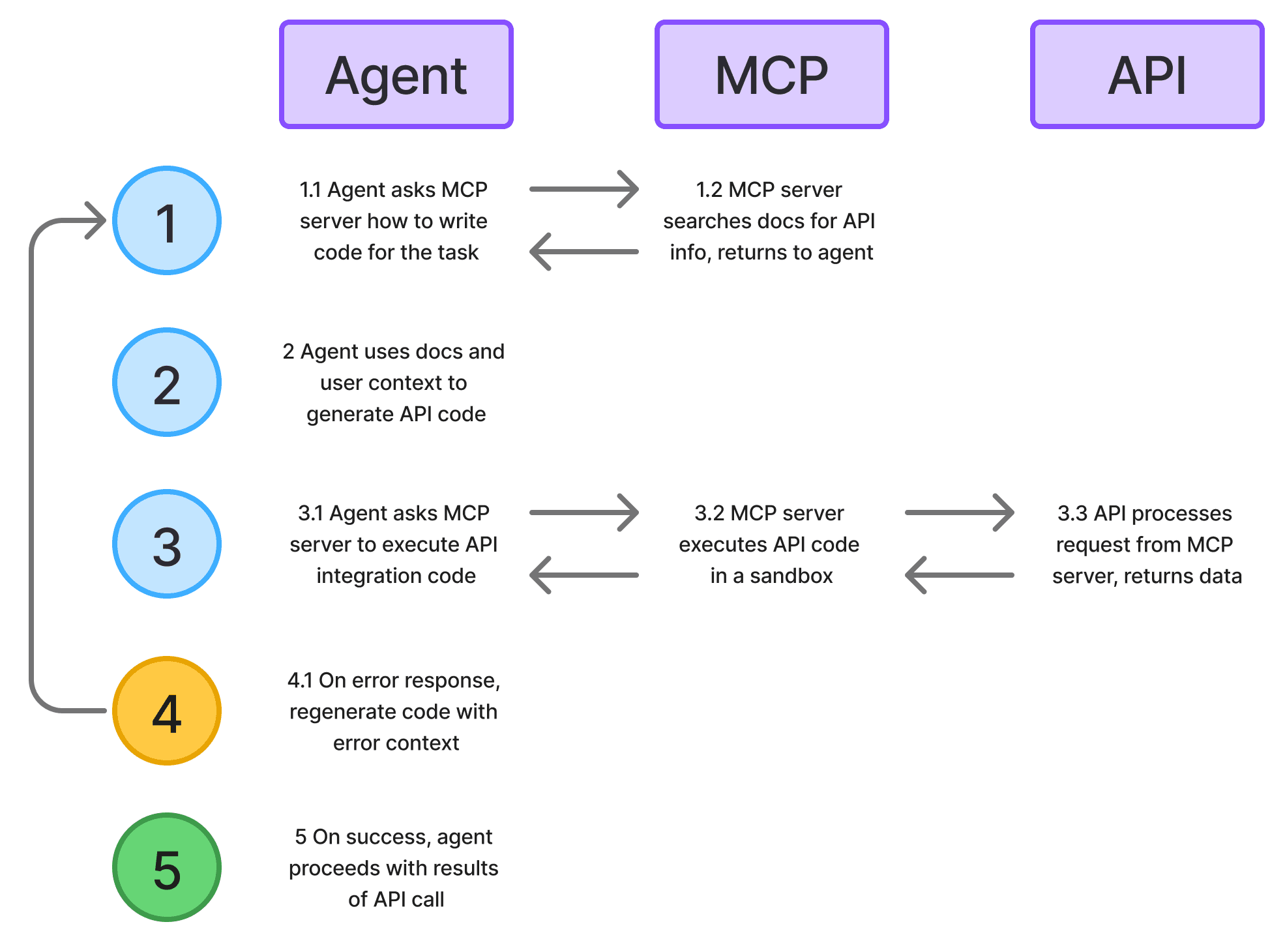
Imagine you are using an agent like ChatGPT, connected to an SDK code mode MCP server for the Stripe payments API. When the agent is asked to do something that needs the Stripe API (e.g. “Issue a refund for all customers that bought striped socks”), it will take steps as illustrated below.
Let’s look at a specific example from our evals. We tested a Stainless-generated MCP server with the Increase banking API, using Claude 4.6 Opus to search docs and generate code to answer the following prompt:
Who did we send expense reimbursements to and for how much?
For this prompt, Claude 4.6 Opus used the Stainless MCP server’s docs_search tool to search the docs twice, once to find out how to search transactions, and once to learn how to view ACH transfers. Here are the tool inputs for the former:
Parameter | Value |
|---|---|
|
|
|
|
The docs_search tool returned the method required, a code example, and information about the inputs to and outputs from the method:

The model then made its first attempt to write code to get the information it was after. The model sent this code to the execute tool of the Stainless MCP server, which ran the code against the Increase API using an authenticated API client (passed as a parameter to the generated code):
This code is syntactically accurate, but it initially returns a 400 error from the API - the Increase API only supports limit values of 100 or less (we’ve found an opportunity to improve API docs!). The error JSON:
For this test case, it took the model 4 code execution runs to get exactly the information it was looking for. The final API code looked like this:
The final response from the model contained the correct information:
SDK code mode specifically excels in accuracy and reduces overall model turns for a few reasons:
Models are excellent at writing code (the key reason all forms of code execution are more accurate than traditional tool calling)
Idiomatic SDKs with good docs are easier for models to write code for, just like human developers
API-specific error messages, doc strings, type hints (checked before API code is executed in Stainless MCP servers), and runtime validation provide high fidelity feedback to the model. This reduces turns spent on debugging incorrect integration code
By comparing SDK code mode to other MCP tool configurations, we can see a meaningful difference in real world API tasks, which we will explore in detail below.
Evals with the Increase Banking API
We benchmarked four different approaches to building MCP servers for the Increase banking API. Each approach gives an LLM (Claude Opus) access to the same underlying REST API, but through a differently-constructed MCP server. We ran 31 eval test cases spanning account lookups, transaction searches, payment reconciliation, and multi-step financial analysis, then scored each on three dimensions. The eval test harness we used can be found here.
The four configurations
Stainless: MCP server auto-generated from the OpenAPI spec by Stainless, with SDK-aware documentation search and code execution.
Cloudflare: MCP server using Cloudflare code mode, providing a
codemodetool that lets the model write and execute code against the API.Anthropic Code Mode: Uses Anthropic's programmatic tool calling and
tool_searchbetas to dynamically discover and call deferred MCP tools.Dynamic: An MCP server that exposes “meta-tools” for gradually discovering API endpoints as tools (
list_api_endpoints,get_api_endpoint_schema, andinvoke_api_endpoint).
Notably absent above is a traditional MCP server with one tool per API endpoint. The token efficiency and accuracy shortcomings are already well documented, so we didn’t include that style of implementation here.
How we scored
Each test case was scored on three axes (0–100%):
Completeness: Did the response include all expected data points? (Heuristic: checks for expected text strings and field values)
Efficiency: Did the agent solve the task without excessive turns or token usage? (Heuristic: penalizes high turn count and token consumption)
Factuality: Was the response exactly correct, with no extra information? (LLM-as-judge evaluation, penalizes long-winded answers)
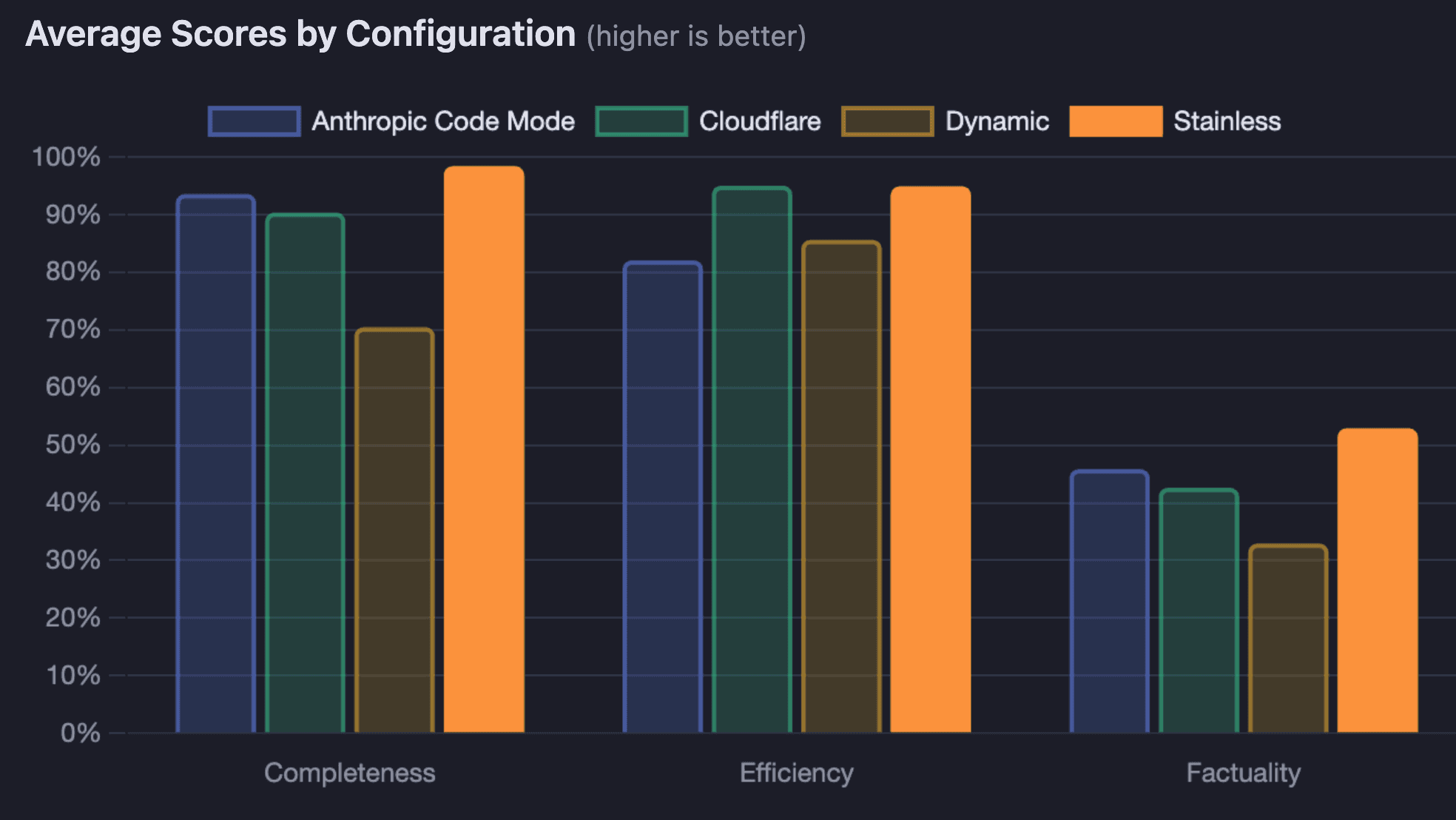
Overall results
The SDK code mode MCP server led across every major dimension:
Configuration | Completeness | Efficiency | Factuality | Avg Duration |
|---|---|---|---|---|
Stainless (SDK code mode) | 98% | 95% | 53% | 48.5s |
Anthropic Code Mode | 94% | 82% | 46% | 68.7s |
Cloudflare | 90% | 95% | 43% | 55.9s |
Dynamic | 70% | 86% | 33% | 65.1s |
Stainless achieved near-perfect completeness (30 of 31 test cases scoring 1.0) while also being the fastest configuration by a significant margin.
Completeness: SDK code mode completes nearly every task
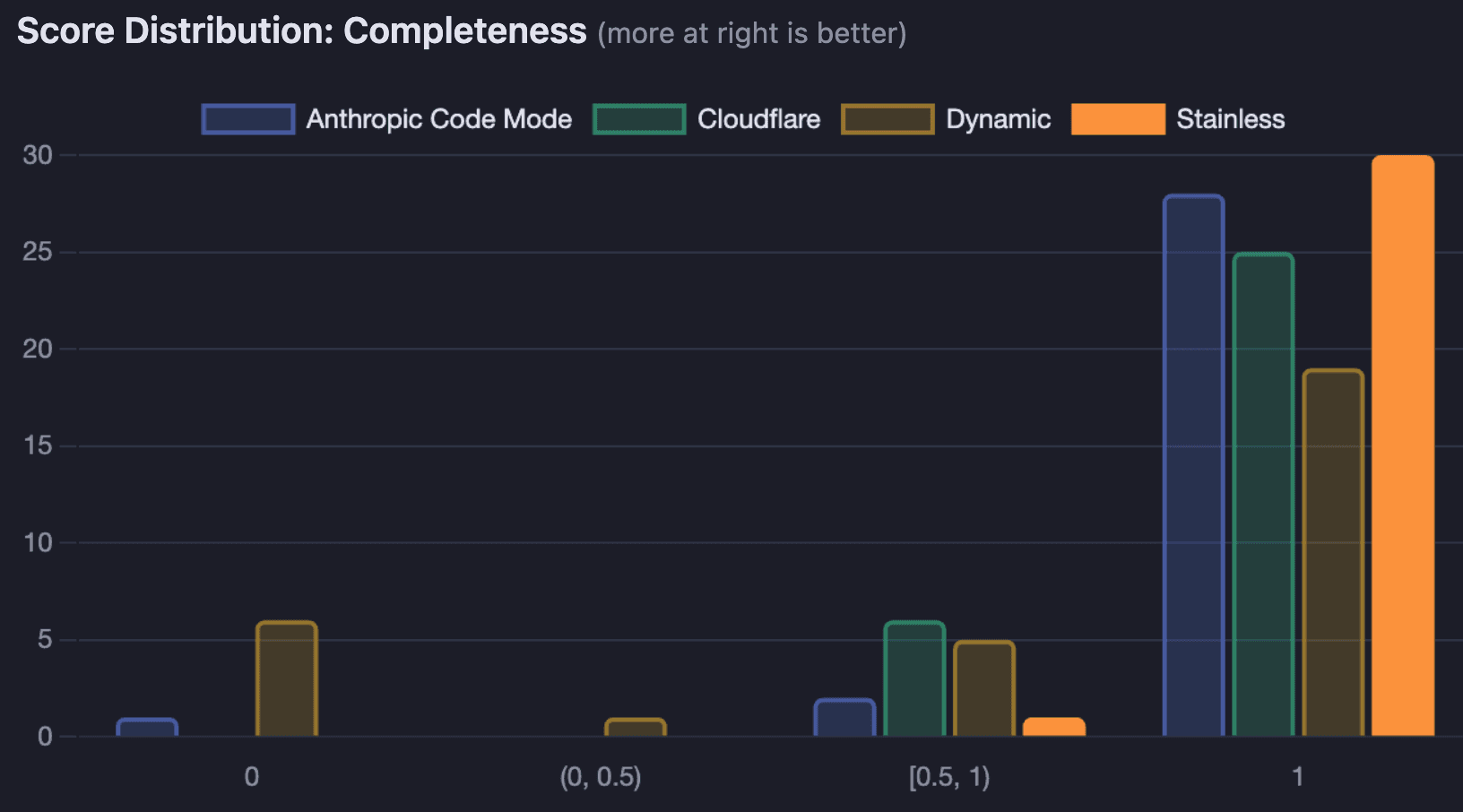
Stainless scored a perfect 1.0 on 30 out of 31 test cases. The biggest differentiator was in transaction-heavy tasks like searching, aggregating, and reconciling payment data. Stainless achieved 100% completeness across all 19 transaction-related test cases, while Dynamic managed only 61% and Cloudflare 87%.
The failures aren't just academic — they're the kind of mistakes that would erode trust in a production system. Here are three real examples from the eval run.
Prompt: "Which companies have sent us bonus payments? Calculate the total."
The correct answer: Titan Corp (7 payments, $40,276.13) and Atlas Group (4 payments, $2,119.54), totaling $42,395.67.
Stainless found all 11 payments across both senders and returned the exact total. Cloudflare searched the same data and confidently reported:
The payments were there - labeled "Performance bonus" and "Referral bonus" in the remittance information of inbound Real-Time Payments. The Cloudflare MCP server searched 100 transactions and 100 RTP transfers but failed to surface them.
Dynamic hit its maximum turn limit and returned no answer at all.
Prompt: "List all dividend payments we have received, including the senders and total amount."
The correct answer: 20 dividend payments from Vertex Capital and Vertex Holdings totaling $112,743.63.
Stainless returned a complete breakdown of all 20 payments with per-sender subtotals. Cloudflare reported:
It checked ACH, wire, RTP, and FedNow channels but concluded: "Your Increase accounts have not received any dividend payments." In fact, 20 inbound RTP transfers had "Dividend payment Q4" in their remittance info.
Anthropic Code Mode returned an empty response.
Prompt: "Find all payments with remittance information mentioning 'Grant disbursement'. Who sent these and what is the total?"
The correct answer: 8 payments from Quantum Research Inc totaling $140,580.12.
Stainless found all 8 and returned the exact total. Cloudflare found only 5 of the 8 payments and reported $98,306.02 — a $42,274 shortfall with no indication that results might be incomplete. Dynamic searched all payment channels and reported:
When the MCP server's tool design doesn't give the model reliable access to the full dataset, the model doesn't just return partial results. It returns confident wrong answers.
Efficiency: SDK code mode approaches worked well
Stainless and Cloudflare both averaged 95% efficiency. They solve problems in fewer turns and with less token overhead. Anthropic Code Mode scored notably lower (82%) because its tool search and code execution loop introduces extra round trips. The model must first search for relevant tools, then write code to call them, adding latency and token cost. Dynamic landed at 86%.
Factuality: room for improvement
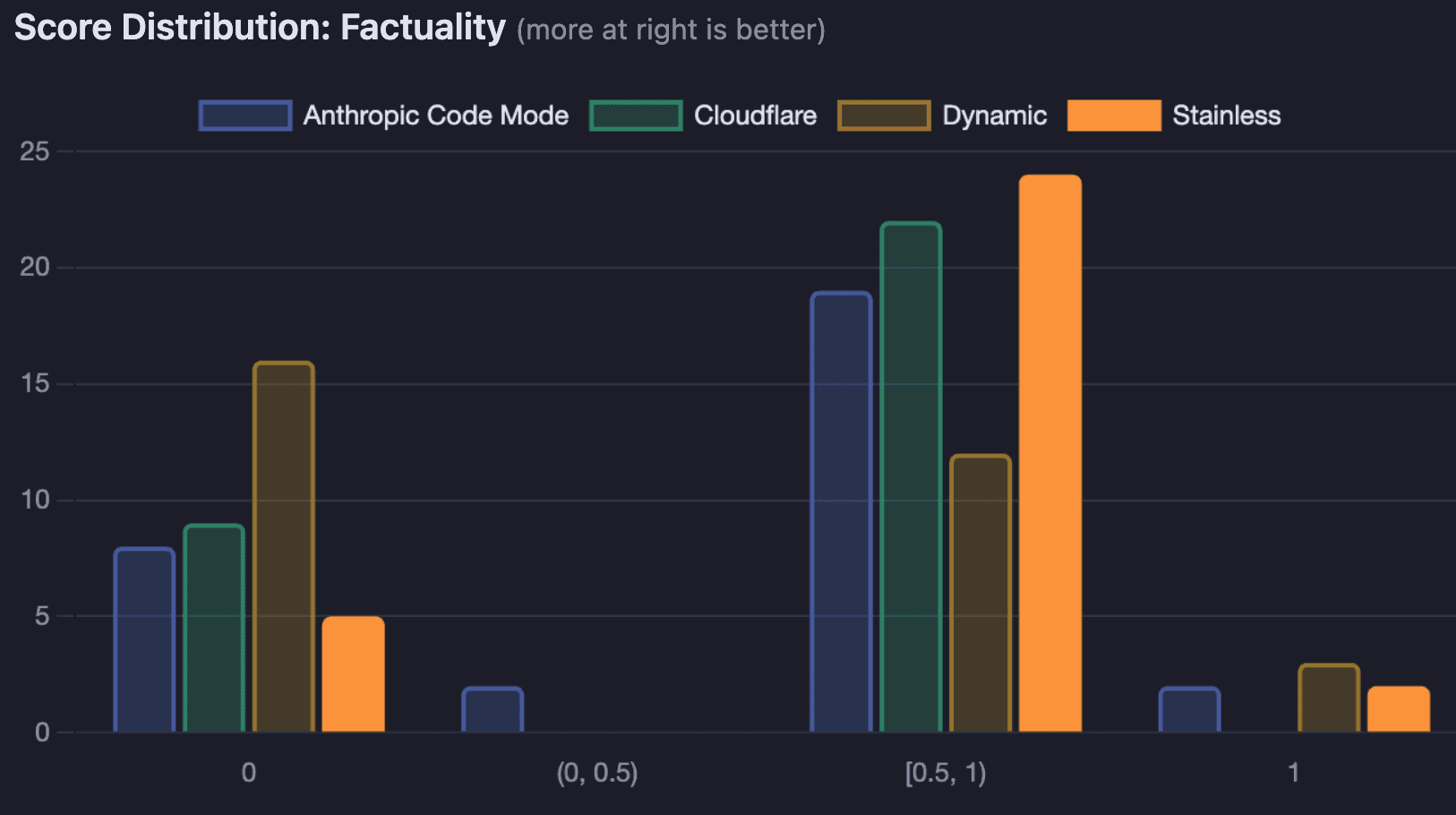
Factuality was the weakest dimension across all configurations, as no approach broke 53%. The LLM-as-judge scorer penalizes responses that contain more information than necessary (e.g. a superset answer), and we’ve found that LLMs like to give more information than strictly necessary in all cases.
SDK code mode had the fewest zero-factuality results (5 out of 31), compared to Dynamic's 16. This suggests that when the MCP server provides well-structured, typed tool outputs with clear documentation, the model is less likely to return extra information it may have found that isn’t relevant.
To check out these results yourself, you can find our test harness and configurations here on GitHub.
Try it with your API
Early experimentation operating APIs via MCP may have yielded unimpressive results. The time has come to reevaluate that experience. With SDK code mode, and the massive investment frontier labs are making in coding models, it’s possible to achieve extremely high levels of accuracy and utility when you ask the model to write code to interact with your API.
There are three key ingredients that enable this advancement:
A consistent, idiomatic SDK with good API-specific error messages - this makes it easy for the model to generate working code, and debug it when necessary.
Documentation, both in your API spec and hand-written narrative docs, that stay in sync with your API - this gives the model the context it needs to use the API correctly.
A generated SDK code mode MCP server with tool configurations optimized for this behavior.
You can experiment with SDK code mode on your API today - let us know what you think!
Originally posted
Mar 2, 2026