Introducing the (experimental!) Stainless SQL SDK generator

Tomer Aberbach
Software Engineer

CJ Avilla
Developer Relations Engineer
If you run analytics, reconciliation, or batch jobs in PostgreSQL, pulling data from REST APIs usually means ETL scripts, intermediary services, or brittle sync pipelines. The data you need is one HTTP request away, but PostgreSQL is not designed to call HTTP endpoints as part of a query plan.
You can bolt on ad-hoc HTTP functions, but you lose typing, pagination ergonomics, and a spec-driven interface.
We built an experimental SQL SDK generator that turns an OpenAPI spec into a PostgreSQL extension that uses PL/Python for HTTP requests. Every API endpoint becomes a SQL function. Every response type becomes a composite type. (We explain why we chose SQL functions over Foreign Data Wrappers below.)
A SQL SDK enables users to query your API using standard SQL.
What you get: REST API calls as SQL functions
To show you how our SQL SDK generator works, we used a subset of the Stripe OpenAPI spec to generate an experimental SQL SDK. You can install it by cloning the extension repo and running ./scripts/repl or by manually building with make install.

Each API endpoint maps to a SQL function. Each resource maps to a PostgreSQL schema. The result is a typed interface to a REST API, accessible from any PostgreSQL client.
How it works
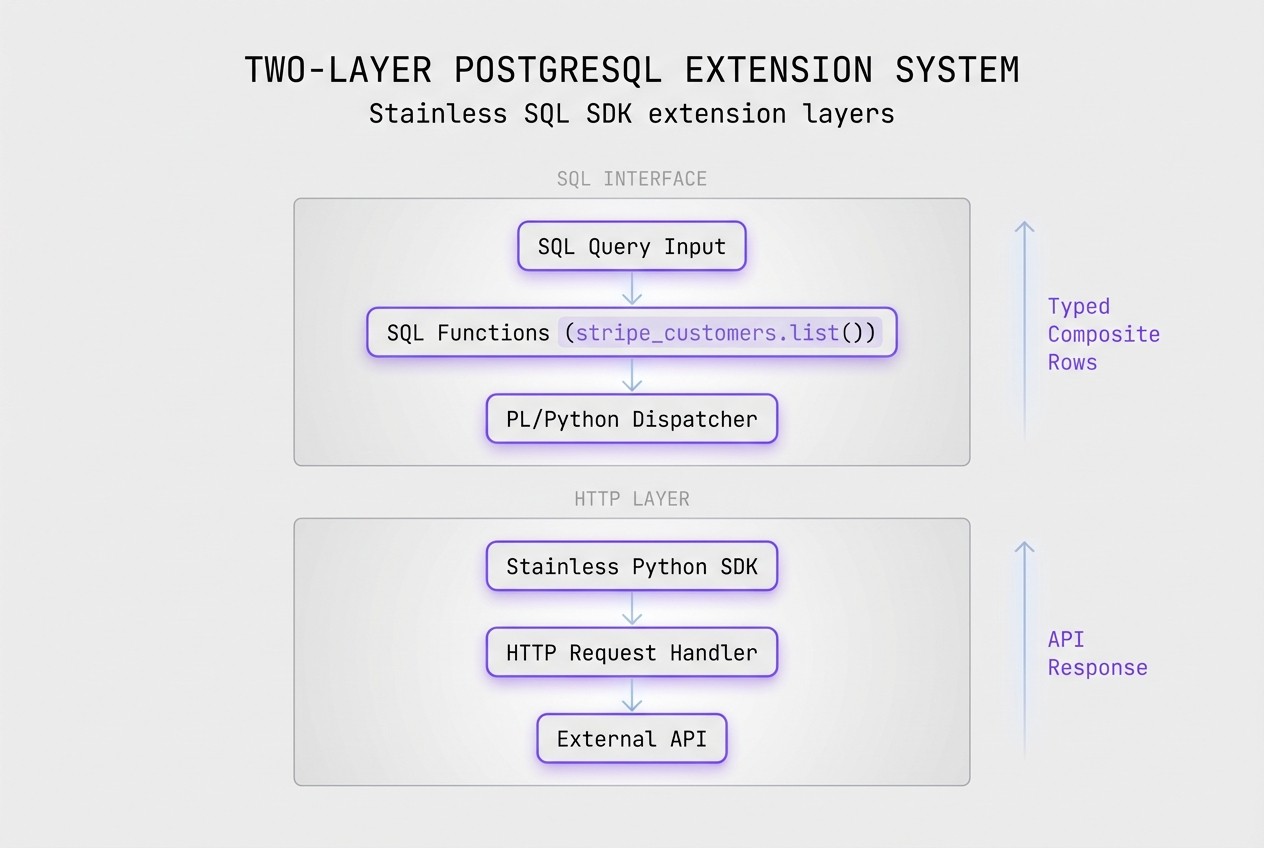
The extension is built on two layers:
PL/Python functions call a Stainless-generated Python SDK to handle HTTP requests, authentication, retries, request serialization, response parsing, and other networking concerns.
SQL function wrappers initialize the client, perform lenient type adaptation from Python objects to PostgreSQL composite types, and expose a typed SQL interface. A single client is initialized per session for performance.
Paginated endpoints employ SQL functions that use WITH RECURSIVE CTEs to repeatedly fetch pages using PL/Python function calls. Because the outer SQL function can be used inline, PostgreSQL can push down LIMIT clauses and stop requesting new pages once enough rows have been produced.
If pagination were implemented entirely in Python, PostgreSQL would buffer the full result set at the PL/Python boundary before applying LIMIT. By keeping auto-pagination in SQL, the query planner retains control over row consumption and can short-circuit additional HTTP requests.
The result is a standard PostgreSQL extension. Install with make install and load with CREATE EXTENSION:
Then configure with ALTER DATABASE.
For example, to configure an API key:
Type-safe composite types, not JSONB blobs
Each API resource maps to a PostgreSQL schema. stripe_customer contains the customer composite type with typed fields: id TEXT, created BIGINT, email TEXT, livemode BOOLEAN.
The generator types fields where the spec is precise. Nested objects map to composite types, and arrays become typed arrays.
You get real column access instead of JSONB->>'field' casting:
For complex parameters, the extension generates make_* constructor functions. The generator produces these from the OpenAPI spec, and they stay in sync when the spec changes.
What it looks like in practice
Create a customer:
List customers:
The extension handles pagination automatically. A LIMIT 200 for an API that returns 100 items per page makes exactly two HTTP requests. Apply LIMIT as close to the API function call as possible so PostgreSQL can stop consuming rows once the limit is satisfied.
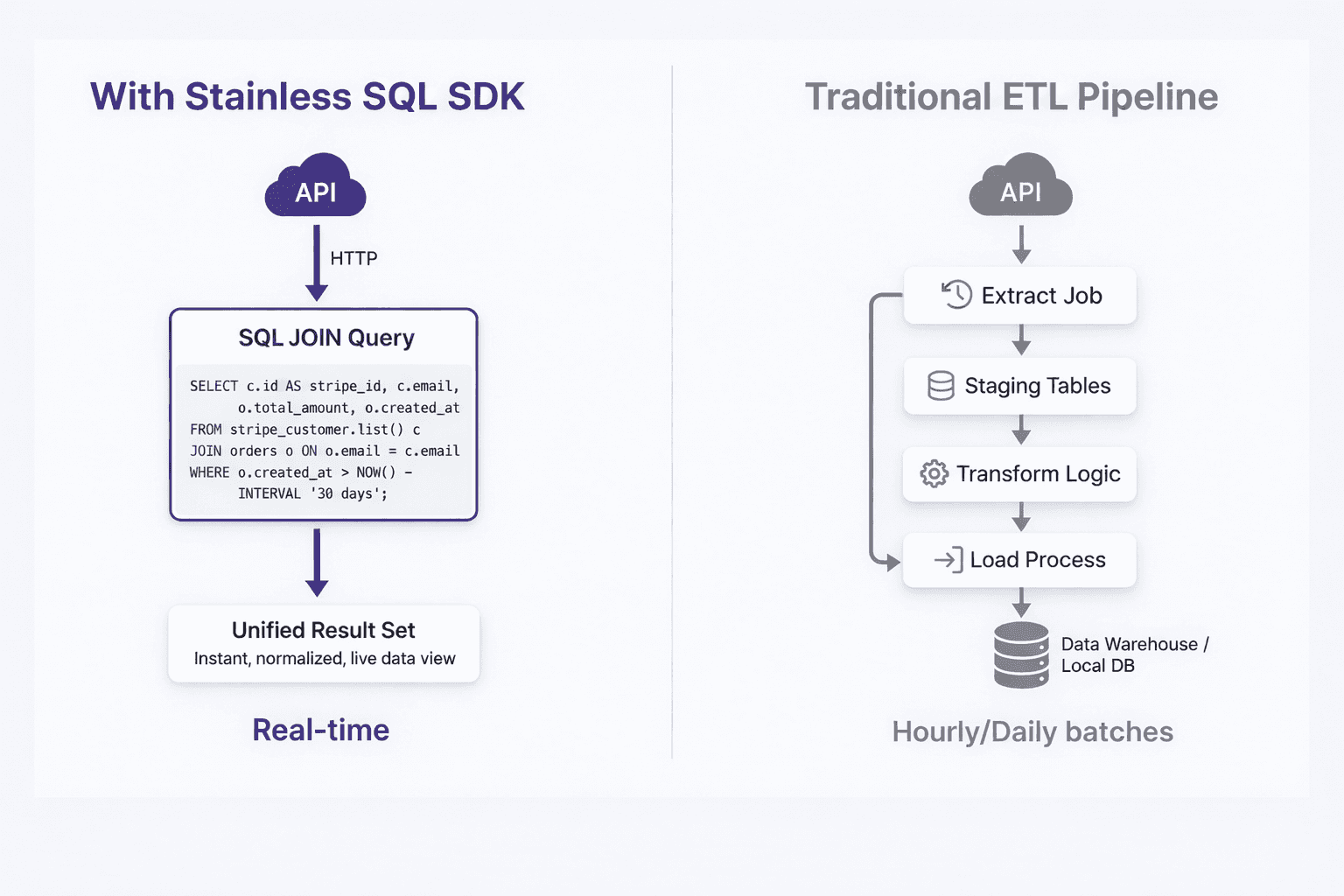
The real payoff is combining API data with your existing tables:
This query joins live Stripe customer data from the API with your local orders table. This replaces an ETL pipeline and staging tables with a single query.
Where SQL SDKs fit
SQL SDKs work well in many workflows, but they’re not a universal solution for every problem. They are most effective when you want to pull API data into analytical queries, scheduled jobs, or batch pipelines that already run inside PostgreSQL.
ETL and data sync
Combine materialized views with pg_cron for scheduled data pulls:
Every four hours, your database has a fresh snapshot of Stripe customers. Query it like any other table.
Business analytics
Ad-hoc queries that combine API data with your operational database: revenue reconciliation, customer segmentation, churn analysis. The queries run where the data already lives.
Batch LLM workflows
Select the latest support tickets, call an LLM classification endpoint, and write labels back to a table for downstream reporting. As LLM APIs publish OpenAPI specs, SQL SDKs make batch inference from SQL practical.
Where SQL SDKs are not a fit
SQL SDKs are not intended for low latency production OLTP paths. Each function call issues one or more HTTP requests, introducing network latency, rate limits, and remote failure modes. PostgreSQL’s planner optimizes relational operators over local data; it is not a cost based planner for REST APIs. Core SQL concepts such as predicate pushdown, join reordering, and index selectivity do not map cleanly to HTTP endpoints, so small query changes can result in additional remote calls. Use SQL SDKs for analytical and batch workloads where expressiveness and integration matter more than tail latency.
Why not generate Foreign Data Wrappers?
Generating Foreign Data Wrappers (FDWs) for APIs is appealing, but there are several drawbacks.
Performance is hard to reason about
A REST API FDW would hide the HTTP requests it makes.
The FDW has to determine which requests to make based on a query, making it a query planner for HTTP requests. A small change to a query could silently result in a less performant plan with many more HTTP requests. This would not be easy to debug.
An FDW over a REST API ends up being a leaky abstraction.
APIs are not always relational
FDWs shine when the data they’re modeling is relational. If the data an API provides is not relational, then it’s not well-suited for being represented as tables in an FDW.
Plain SQL functions work for any API.
A new interface to learn
Modeling API data in FDW tables would result in a different interface from the API and its SDKs, which means your users would have to learn a new API.
Plain SQL functions grouped by resource matches the existing structure of your API and its SDKs.
Current status: experimental
The SQL SDK generator works best with OpenAPI 3.x specifications that use standard request and response bodies and predictable pagination patterns. We generated a Stripe SQL SDK as the first example, but the generator is not Stripe-specific.
This is an experimental release. We're sharing it because we want feedback from developers who work at the intersection of APIs and databases. We're also expanding coverage and want to hear about OpenAPI specs that break the generator.
Expect breaking changes. This is not ready for production workloads. We are actively developing the generator and want to hear which use cases matter most to you.
If you’re using our SQL SDK generator in any capacity we’d love to hear from you. Let us know what you’re working on, if you run into any issues, or if you have feedback.
Try it out
The Stripe SQL SDK is available as a reference for what the generator produces. Clone the repo, run make install, load with CREATE EXTENSION stripe, and set stripe.secret_key.
Want a generated extension for your API? Sign up here to get early access and tell us which APIs you want to query from SQL. We are working toward supporting any API with an OpenAPI spec.
Originally posted
Feb 18, 2026